
복습
인덱스(Index) 본문
인덱스(Index)란?
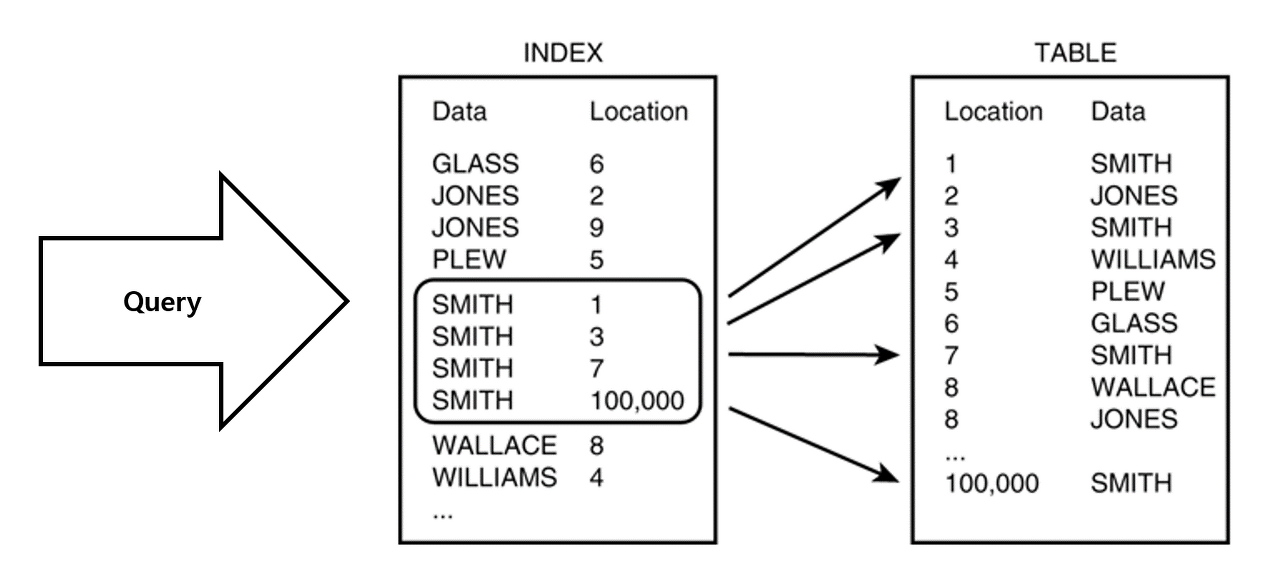
- 추가적인 쓰기 작업과 저장 공간을 활용하여 데이터베이스 테이블의 검색 속도를 향상시키기 위한 자료구조
- 책의 맨 앞 또는 맨 뒤에 있는 색인과 같다.
- 테이블의 모든 데이터를 검색하면 시간이 오래 걸려 데이터와 데이터의 위치를 포함한 자료구조를 생성하여 빠르게 조회할 수 있도록 한다.
- 인덱스 생성 시 해당 컬럼의 데이터를 정렬하여 별도의 메모리 공간에 데이터의 물리적 주소와 함께 저장
- 인덱스 생성 시 데이터를 오름차순으로 정렬하기 때문에 정렬된 주소체계라고 표현할 수 있다.
- select, update, delete의 성능이 향상된다.(모두 대상을 조회해야 하기 때문)
인덱스의 장점과 단점
- 장점
- 데이터가 정렬되어 있어 조건 검색이라는 영역에서 굉장한 장점
- 테이블을 조회하는 속도와 그에 따른 성능을 향상시킬 수 있다.
- 전반적인 시스템의 부하를 줄일 수 있다.
- 단점
- 인덱스를 관리하기 위해 DB의 약 10%에 해당하는 저장공간 필요
- 처음 index를 생성하는데 많은 시간 소요
- 인덱스를 관리하기 위해 추가 작업 필요
- 인덱스를 잘못 사용할 경우(insert, update, delete 등 데이터 변경 작업이 자주 일어나는 경우) 오히려 성능이 저하되는 역효과 발생
인덱스 생성 전략
- 인덱스는 열 단위에 생성
- where과 같은 조건절에서 사용되며 자주 사용되는 곳에 생성
- 테이블의 데이터는 순서 없이 뒤죽박죽 저장되어 where절의 조건에 맞는 데이터를 찾을 때 처음부터 끝까지 다 읽어야 한다(Full Table Scan)
- 하지만 인덱스 테이블 스캔 시 인덱스 테이블은 정렬되어 있기 때문에 조건에 맞는 데이터를 빠르게 찾을 수 있다.
- order by절에 자주 사용되는 컬럼에 생성
- order by는 굉장히 부하 많이 걸리는 작업인데, 인덱스를 사용하여 order by의 정렬 과정을 피할 수 있다.
- 인덱스를 사용하면 이미 정렬되어 있기 때문
- 정렬 되어 있기 때문에 MIN, MAX 함수 처리 시 레코드의 시작값과 끝값 한 건씩만 가져오면 되어 효율적이다.
- 데이터 중복도가 낮은 컬럼에 생성(카디널리티가 높다)
- 조인에 자주 사용되는 컬럼에 생성
- 데이터 변경(삽입, 수정, 삭제) 작업이 자주 일어나지 않는 곳에 생성
- 항상 최신의 데이터를 정렬된 상태로 유지해야 하기 때문에 데이터의 변경이 자주 일어나면 부하가 많이 발생
- 사용하지 않는 인덱스는 제거
- 데이터의 양이 많은 테이블에 사용
클러스터 인덱스(Clustered Index), 보조 인덱스(Non Clustered Index or Secondary Index)
클러스터 인덱스(Clustered Index)
- 특정 나열된 데이터를 일정 기준으로 정렬해주는 인덱스
- 테이블당 한 개만 생성 가능(클러스터형 인덱스를 생성하는 곳에 따라 시스템의 성능이 달라짐)
- 데이터가 정렬되어 있어 보조 인덱스보다 검색 속도가 빠름
- 하지만, 입력/수정/삭제 작업은 느림(정렬때문)
- MySQL의 경우 Primary Key를 클러스터형 인덱스로 자동 생성
- PK가 없다면 unique 제약조건이 있는 인덱스를 클러스터형 인덱스로 자동 생성
- ex) 영어사전
보조 인덱스(Secondary Index)
- 개념적으로 후보키에만 부여 가능한 index
- 데이터가 정렬되지 않으며 별도의 페이지에 인덱스를 구성
- 클러스터형 인덱스보다 검색 속도는 느리지만 데이터 변경 시 성능 부하가 적음
- 테이블당 여러 개 생성 가능
- ex) 책의 색인
후보키
주민번호와 같이 각 데이터를 인식할 수 있는 최소한의 고유 식별 속성 집합
최소성과 유일성을 만족하며, 기본키가 될 수 있다.
참고
https://choicode.tistory.com/27
[DB] 데이터베이스(DB) 인덱스(Index) 란 무엇인가?
들어가면서.. DB를 사용하면서 데이터의 양(row)에 따라 실행 결과의 속도가 차이가 나는 것을 알고 있었다. 특히 데이터의 양이 증가할수록 실행 속도는 느려지고, JOIN이나 서브 쿼리 사용 시 곱
choicode.tistory.com
https://mongyang.tistory.com/75
[SQL] 인덱스 (클러스터, 비클러스터) 개념
인덱스. 1. 개념 A. 간단한 비유로 일반적으로 책 뒤쪽에 위치하는 ‘찾아보기’를 들 수 있다.B. 일 예로, ‘홍길동전’에서 ‘율도국’이라는 단어를 찾는다고 가정해보자. 만일 이 책에 ‘찾아
mongyang.tistory.com
[자료구조] 간단히 알아보는 B-Tree, B+Tree, B*Tree
위 글을 보고 정리를 하지 않을 수 없었습니다. 가슴이 시키네요;; 그렇다면 바로 B-Tree, B*Tree, B+Tree의 특징에 대해서 알아봅시다. 목차 0. 이진트리 B-Tree, B*Tree, B+Tree에 대해서 알아보자면서 갑자
ssocoit.tistory.com
https://mangkyu.tistory.com/96
[Database] 인덱스(index)란?
1. 인덱스(Index)란? [ 인덱스(index)란? ] 인덱스란 추가적인 쓰기 작업과 저장 공간을 활용하여 데이터베이스 테이블의 검색 속도를 향상시키기 위한 자료구조이다. 만약 우리가 책에서 원하는 내
mangkyu.tistory.com
'CS > DB' 카테고리의 다른 글
| 인덱스 자료구조 - 해시 테이블(Hash Table), B-Tree, B+Tree, B*Tree (0) | 2023.05.07 |
|---|
